数据库事务
事务(Transaction)就是并发操作的基本单位。一个事务就是一些列操作,这些数据库操作要么全部执行,要么全部不执行,而且不会破坏数据库的一致性。其符合ACID四个特性:
原子性:指事务的操作要么全部成功,要么全部失败回滚;
一致性:指事务必须使数据库从一个一致性状态变换到另一个一致性状态;
隔离性:多个用户并发访问数据库,每个用户的事务不会被其他事务干扰,相互隔离;
持久性:事务一旦被提交,对数据库的改变就是永久性的。
数据库索引
索引就是对数据库表中一列或者多列值进行排序的结构。是一种帮助高效获取(查找)数据的数据结构。
索引通常使用B树及其变种B+树
相关链接http://blog.codinglabs.org/articles/theory-of-mysql-index.html
索引的设计就是要提高数据查找速度,但是对于数据库而言,速度最大制约就是硬盘的IO速度。而索引文件有时也非常庞大,不可能全部取出放到内存中查找。因此就要设计最合适的索引结构,使得在检索索引的时候IO开销较小。
对于B数,出度d可以是一个非常大的数字(超过100)而根节点常驻内存,每一次二分查找指向下一层的节点时,只需要一次IO就可以将下一层节点上的信息取出,继续进行二分查找。那么查找到最终的数据仅仅需要h次IO,这个h可以很小,通常不超过3。因此就有很好的IO性能。
而红黑树这种数据结构,一是h很深,二是相邻节点之间物理地址距离很远,不适合磁盘的局部性特点。
B+数更适合外存索引,是因为搜索中间节点时,搜索的仅仅是真实数据的索引,中间节点不存储数据的data域,因此可以将出度d设为很大,进一步增加了性能。(一次IO取到的数据中d更多,如果每个节点都要有个data域,那么一页的数据就会变少,d就变小)。
MySQL的索引具体实现,需要和引擎联系在一起,见下一节。
说一下全文索引:
数据库引擎(innoDB等)
MySQL中,索引是一个引擎级别的概念,必须和引擎一起讨论,不同引擎不一样的索引结构。
MySQL的引擎有很多,这里主要讨论MyISAM和InnoDB。
二者的特点和区别概述:
MyISAM:查找效率高,不支持事务,不支持外键,保存了表的具体行数(内置了一个计数器),是非聚类索引,支持全文索引。
InnoDB:最新(5.5开始)MySQL的默认引擎,查找效率也不低,支持事务,支持外键,不保存表的行数,聚类索引,不支持全文索引(mysql5.6开始也支持了)。
现在已经可以使用5.7版本了。。。。优秀的innoDB
锁
MyISAM:表级锁。
InnoDB:行级锁和表级锁,默认行级锁。(当然行级锁并发优秀,但是开销大)
主键
MyISAM:可以没有主键。
InnoDB:没有主键也会跟你分配一个6字节的主键。
MyISAM索引实现
MyISAM使用B+树的索引结构,叶节点的data域存储的是数据记录的地址。如图(图片来自上面给出的链接,侵删)
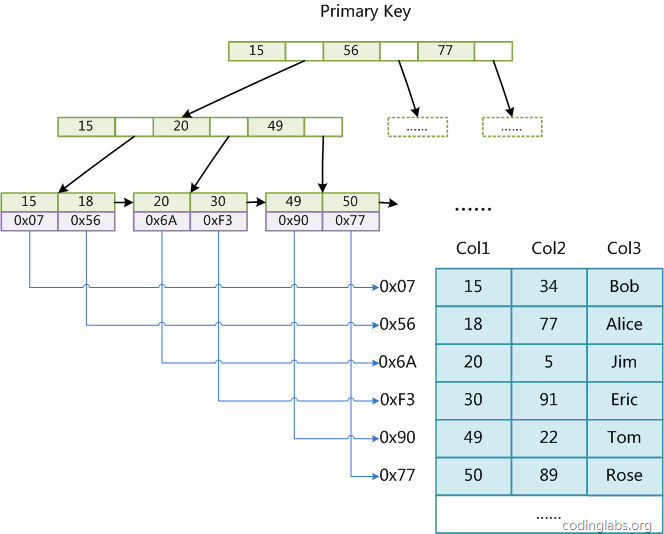
上图是对一个数据表的主键的索引(主索引)示意图,MyISAM中的辅助索引也是这样,只不过key可以重复而已。所以查询的过程也非常清晰,对B+的根节点开始做二分,直到找到叶节点,然后遍历叶节点,找到data域,再去对应地址取数据。而这一系列操作只需要两次IO,假设索引文件很小,一次就可以取到内存中。
非聚类索引仅仅是因为要和下文的聚类索引相区分才使用的。
InnoDB索引实现
InnoDB的索引,又称为聚类索引。当然也是用的是B+树的数据结构。但是和MyISAM有很多区别:
第一,InnoDB的数据本身就是索引文件,而不是像上面的索引数据分开的结构。也就是说叶节点的data域保存的就是数据本身,中间节点的key就是主键,因此innoDB必须有主键。
然后对任意一列做辅助索引,每个节点的key就是那一列的属性值,但是最后叶子节点的data域却是主键值。
可以看出这种聚类索引的查找过程,如果从主索引开始还好,如果从辅助索引开始,那么第一次查找找到的是主键的值,第二次再用主键值在主索引中查找,才能找到完整的data信息(记录)。需要多一次。
因此对于innoDB的数据主键,最好采用自增的字段,一是短,二是单调。这样在B+树调整结构,以及辅助索引的存储,都会很高效。
索引调优
联合索引
又称组合索引,就是将几个属性联合起来作为判断key大小的依据,对于abc的组合索引,原来的key就是a1>a2就行,现在还要a1>a2,或者a1=a2&&b1>b2,或者a1=a2&&b1=b2&&c1>c2。以这样的顺序判断两行记录的大小关系,也就是在索引中的前后关系。当然,abc的组合索引也是ab的组合索引也是a的单个索引。其记录在在各个索引中对应的位置是不变的。
SQL语句
非关系数据库
上面所有部分均是以MySQL等为代表的关系数据库的知识,现在开始说一些非关系数据库。
Redis
redis单例提供了一种数据缓存方式和丰富的数据操作api,但是将数据完全存储在单个redis中主要存在两个问题:数据备份和数据体量较大造成的性能降低。这里redis的主从模式为这两个问题提供了一个较好的解决方案。主从模式指的是使用一个redis实例作为主机,其余的实例作为备份机。主机和从机的数据完全一致,主机支持数据的写入和读取等各项操作,而从机则只支持与主机数据的同步和读取,也就是说,客户端可以将数据写入到主机,由主机自动将数据的写入操作同步到从机。主从模式很好的解决了数据备份问题,并且由于主从服务数据几乎是一致的,因而可以将写入数据的命令发送给主机执行,而读取数据的命令发送给不同的从机执行,从而达到读写分离的目的。
redis的主从模式:一个主机多个从机,主机只负责数据的写入和读取,而从机负责向主机同步数据以及数据的读取,这样在读取时可以提高性能,实现读写分离。也可以方便的支持数据的迁移。
支持多种类型:string hash set zset List
两种持久化: RDB和AOF
RDB:RDB方式,是将redis某一时刻的数据持久化到磁盘中,是一种快照式的持久化方法。
AOF:AOF方式是将执行过的写指令记录下来,在数据恢复时按照从前到后的顺序再将指令都执行一遍。
AOF的效果好但是RDB效率高。RDB会有数据的遗失
Memcached
E-R图以及转换关系模型
方框表示实体,椭圆表示属性,实体之间的联系用菱形(一个或者多个)表示,菱形可以表示出1:1,1:n,m:n等关系。转换为关系模型时注意:
1:1的关系只需要将一个主键作为另一个外键即可。
1:n的关系是需要将1的主键作为n方的外键。
m:n的关系比较复杂,需要单独将每一个,m方和n方的主键都存在一条记录里,如果需要还需要保存联系的名称。比如用户对某个对象的操作。可以是多个用户对多个对象进行操作,操作类型还可以有注册,删除,增加等等。