自我介绍
大家好,我是XX号面试者,是一名研三的应届生,就读于北京邮电大学,网络技术研究院,专业是计算机科学与技术。本科也就读于北邮,专业是电子科学与技术。今年暑期我在字节跳动,今日头条实习,负责APP服务端的开发,负责日常需求的迭代,参与了很多方案设计与bug修复。因此对后台开发的流程和架构有一些经验。在学校主要研究网络架构和优化,毕业论文的方向就是无线流媒体传输层的优化,因此对网络协议和技术也有一定的了解。当然,我经历过考研,对计算机基础也是有一定了解。我比较熟悉的语言是java。在团队中,我喜欢主动承担责任,主动推动任务进度去完成任务。
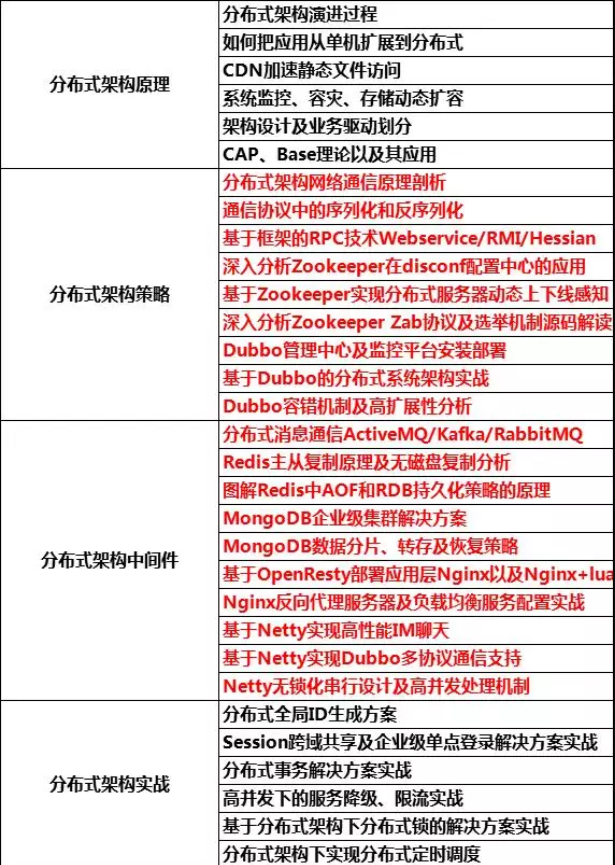
数据结构
1.排序算法
堆排序:
建堆和调整:
首先按照数组的顺序构建完全二叉树,即每一个序号为n的节点,其左孩子是2n+1 有节点是2n+2 (根节点的序号是0)
然后从最后一个非叶子结点开始调整,调整的范围是以该节点为根节点形成的子树。
网上借来的图片,数组A为49,38,65,97,76,13,27,49,目标是组成小根堆(a)是直接按照数组顺序构造的完全二叉树,
第一步的调整就是从序号N/2的节点开始,即97节点,调整的范围是97和49构成的子树。调整的方法是选根节点左孩子节点以及右孩子节点中最小(大)的和根节点交换。因此调整的结果是97和49交换。形成了(b)。
之后如果某一个孩子节点和根节点交换之后,以该孩子节点为根节点形成的子树可能会被破坏规则。
比如下一个调整的节点是65节点,调整之后它和他的左孩子节点13交换。在调整38节点,它不需要交换。在调整最上面的49节点,首先要和13交换,这时,原来以13节点的为根节点的子树的规则被破坏了。因此,交换之后,要递归对交换节点之后的子树做一次调整。也就是某个孩子节点和根节点交换了,递归调整该孩子节点下面的子树。因此对于图中49的节点和13节点交换之后还要再对子树进行调整,49节点再和27节点减交换,完成下沉。
形成(e)。
然后排序的过程很简单,从最上面的根节点取出保存,该节点是最大(小)的值,再将序号最大的节点放在根节点的位置上,即A[0]= A[N] N=N-1 之后根节点就破坏了堆的性质,于是从根节点开始调整,将根节点一步一步下沉,调整。因为最多只需要交换的次数就是数的高度。将根节点下降到叶子节点。因此时间复杂度每一次为logN
linux系统
海量数据
Socket 是应用层和传输层之间的一个抽象层,它将 TCP/IP 的复杂操作抽象为几个简单的借口供应用层调用,以实现进程在网络之间的通信
而进程网络通信间的唯一标志则是 ip 地址+传输协议+端口号
Thrift 序列化的协议:JSON Protobuf Avro Binary Compact
Compact : 一种序列化规范
Binary: 二进制码
对照这个模型,Thrift的核心组件有:
TProtocol 协议和编解码组件
TTransport 传输组件
TProcessor 服务调用组件
TServer,Client 服务器和客户端组件
IDL 服务描述组件,负责生产跨平台客户端
thrift,有自己的网络通信框架+thrift 对象序列化协议+thrift 调用控制协议
Rpc remote procedrue call 远程过程调用 目的是通过网络通信向远程计算机上请求服务,调用函数,就像调用本机上的函数一样,而不必关心实现的细节。请求服务也可以理解成进程之间的数据交换
一般 RPC 框架也是由三部分组成,
最底层的就是网络通信,一般都是用 tcp 协议
网络通信之上就是编解码或者序列换反序列化的协议,用来将网络中传输的字节流,转化为对应的内存中的表达方式
再往上就是如何将这些网络传输的信息通过本地调用进行相应的处理,获取返回值。thrift 中的表述是从数据流中读数据和向数据流中写数据。
一般 RPC 都有服务端和 客户端
其实就是对应上面的描述做一个功能的集合,客户端用于发起请求,服务端用于处理请求
当然这种模式只支持请求,无法支持推送 push 的功能。
Rpc 框架同时也要提供高并发,长链接,分布式,异步通信,大数据量等等特性,根据框架不同实现的效果也不同
负载均衡 服务发现 连接池(长链接 短连接) 令牌桶 golang本地缓存
服务发现与心跳机制
通过 PSM 名称调用 Consul 的 HTTP 接口,可以获得 PSM 对应服务所有节点的 IP 和 Port,进而可以获取 Thrift 和 DB 等服务。通过实验,当前不同机房的 PSM 是不打通的。
Kite 框架中完成了服务注册 到 服务发现的过程
服务发现: 在第一次调用call方法的时候初始化各个中间件,其中就有服务发现的中间件,获取 rpc 的信息,具体发现是使用本地缓存,并定义 fether,通过 http get 向 consul 服务器获取对应服务的 ip 和端口号
心跳机制,心跳机制用于检测对方是否正常工作,客户端定向向服务端发送心跳检测包,用于告诉服务端我还在工作。到底是客户端还是服务端发送心跳检测包,视情况而定,一般处于效率的考虑,是客户端发送。
长链接与短连接:
HTTP 的长链接与短连接本质上是 TCP 的长链接与短连接,是 HTTP1.1起默认使用长链接,Connection:keep-alive,在响应头就会出现上述代码。
长链接的每次 HTTP 请求之后不会断开 TCP连接,
HTTP2.0 二进制分帧,多路复用即多重的请求响应消息,首部压缩,服务端推送
Etcd 一致性分布式键值系统,用于共享配置和服务发现
多线程 与 线程池
java 多线程:
线程的创建,几个函数的功能:wait notify join sleep start run interrupt
线程的同步: 锁 synchronized 数据同步:volatile
Docker 一种容器,实现了类似于虚拟机的功能,是一种新的虚拟化方式
Docker 包括三个基本概念
- 镜像(Image)
- 容器(Container)
- 仓库(Repository)
git
MQ消息队列
上下游通信机制,实现逻辑解耦和物理解耦,是一种跨进程通信的方式
缺点:
- 系统复杂,多了一个MQ组件
- 消息传递时延增加
- 可靠性和重复性相互制约
- 上游无法得知下游的执行结果(关键)
因此调用方如果依赖调用的结果执行判断,不能使用消息队列
高并发场景
业务难题:
高负载,并发量大,此时网络带宽负载高,而且尤其是数据库,在多个用户请求下,进程数增加,上下文切换代价高昂。而且一旦业务耦合高的情况下,一些服务不可用,很可能会导致其他服务挂调,一台服务器挂了,流量分散到其他服务器上,也可能压垮其他服务器导致血崩。
架构设计:
拦截请求,并发场景请求大多是无效的,有效的仅是少数,如秒杀场景,可以在上游就进行拦截
充分利用缓存redis,
利用消息中间件,使用异步的方式拦截请求,实现削峰,然后根据下游处理能力,实现消息的拉取和处理。
具体设计:
前端可以实现拦截,比如一段时间只能点一次
后端根据uid做过滤,然而用户量大的情况下,服务器压力还是很大,于是可以使用消息队列和缓存:
消息队列实现对请求的缓存,当消息队列的请求收到确认的消息后才会被下发到数据库。比如秒杀时所有请求中只有几个请求才会是秒杀成功,那么消息队列收到秒杀成功的确认消息才会进行对数据库的修改。
缓存读和缓存写
利用redis进行读缓存,以及进行写的缓存,之后统一持久化到数据库中。
总结:手段就一下几类:
限流,削峰,异步处理,使用缓存,以及可以扩展,以后用户再多,加机器就可以了。
RPC
rpc的负载均衡
客户端的负载均衡,使用负载均衡算法选取一个节点进行访问。
负载均衡算法举例:
- 轮询(Round Robin)
- 加权轮询(Weight Round Robin)
- 随机(Random)
- 加权随机(Weight Random)
- 源地址哈希(Hash)
- 一致性哈希(ConsistentHash)
- 最小连接数(Least Connections)
- 低并发优先(Active Weight)
高可用(HA)近似于容错,兜底
设计模式
JVM
jvm内存
方法区,堆 虚拟机栈 本地方法栈 程序计数器 后三个线程独享,前两个线程共享。
- 程序计数器,当前线程执行字节码的行号的指示器。因此要线程独享。
- 虚拟机栈,通俗意义上的栈内存,用于存储局部变量表,操作数栈,方法出入口等信息。局部变量表就存放了编译期间各种已知的基本数据类型。
- 本地方法栈,和虚拟机栈类似,虚拟机栈是java执行的字节码(java方法)服务,而本地方法栈则是为虚拟机使用的native方法服务的,根据虚拟机自己的规范而不同。
- 堆, 就是对象实例,数组等存在的内存空间,也是gc主要负责垃圾回收的空间。
- 方法区, 存储已经被虚拟机加载的类,常量和静态变量等。
垃圾回收
判断对象是否可回收的算法:
- 引用计数算法,对每个对象的引用进行计数,引用加一,失效减一,当计数为0时,就为无效对象,可以被回收。
- 可达性分析算法, 从一系列gc root的对象作为起点向下搜索,走过的路径称为reference chain,当对象和gc root没有任何引用链连接值,称为此对象为不可达,就是可回收的对象。
垃圾收集算法:
- 标记-清除算法,两个动作,标记所有可回收的对象,之后统一释放内存,但是这两者效率都不高,而且容易出现内存碎片,当需要分配大内存的对象时,可能需要再一次的垃圾回收。
- 复制算法, 将内存分为两块区域,每次只在一块区域上分配内存,当某一块区域满了之后,将生存的对象复制到另一块区域,然后整个释放掉本块内存。代价就是牺牲了总体内存的大小。
- 新生代的 eden 和 survivor, 复制算法的一个实例,两种内存区域的大小是8:1,内存分为一个eden和两个survivor。每次使用一个eden和一个survivor区域,复制的时候将两个区域存活的对象复制到另一个survivor中,再清空内存。当然,如果另一个survivor装不下的话,只能通过利用老年代来进行分配担保。
- 标记-整理算法,相对于标记-清除算法,标记之后不清除,而是将存活的对象向一个方向移动,之后再将端边界之外的内存清理掉。
- 分代收集算法,一般分为新生代和老年代,新生代对象生存时间短,每时都有大批量对象死去,因此适合复制算法,而老年代中对象存活率高,也没有其他空间对其进行分配担保,因此必须使用标记清除或者标记整理算法。
附 面经一份
链接:
https://www.nowcoder.com/discuss/91999?type=2&order=0&pos=49&page=1
- 自我介绍
- 说一下Java和其他语言相比有什么不同
- 重点说一下Java和C相比什么区别,Java的好处是哪些
- 你刚才提到了平台无关性,Java为什么平台无关
- 你刚才提到了jvm,还有class文件。说一说具体的加载流程
- 你刚才还说到了java堆的垃圾回收。能说说垃圾回收的方法么
- 你都知道那些实现垃圾回收的算法,再说说分别都在哪里用到
- 除了分代回收,你还知道其它种垃圾回收方法么
- 可以自己设计一种针对老年代的回收方法么(一脸懵逼)
- redis和其他缓存相比有哪些优点呢
- 你刚刚提到了持久化,能重点介绍一下么
- 接下来这个问题我没太听懂,我理解的是问的AOF中append的好处。但是面试官说不是。后来就跳过去了
- 我们把数存到redis的一个节点,在另一个节点却能查询到,这是怎么实现的呢(这里我好像答偏了,讲了讲哈希取模和一致性哈希来计算在哪个节点,不过面试官并没有打断)
- 说一下强一致性和最终一致性 答:强一致更新后读取的都是最新的值,最终一致性,更新后在一段时间之后才是最终更新的值,是弱一致性的特例。弱一致性,不能保证读到的是最新的值。
- Redis用的什么协议
- Gossip协议下面又是什么协议呢
- Tcp是怎么实现可靠性的
- 我们总说TCP/IP,那么ip协议又是什么呢
- 计算机网络模型的那几层说一下(我能说我又忘了么QAQ,明天我要打印下来粘在墙上!)
- 说一下操作系统中的进程调度算法(这是个啥)
- 关系型数据库平时用哪些
- 知不知道怎么检测select语句在哪里可以优化,查询的时候有没有走索引(尴尬,不会。)
- 了解索引不,说说是索引的数据结构
- 你刚刚提到了B+树,那B+树和普通的树有什么区别呢
- Spring也是自学的么,讲一讲aop,说一说它用到了什么设计模式
- Aop用的是哪种代理模式,具体说一下
- 再说说你实习时候的项目balabala
- 你还有什么问题么
相关知识点